sqlite安装及创建数据库
首先进入Sqlite官方网址:
https://www.sqlite.org/download.html
然后下载下面框起来的两个压缩文件
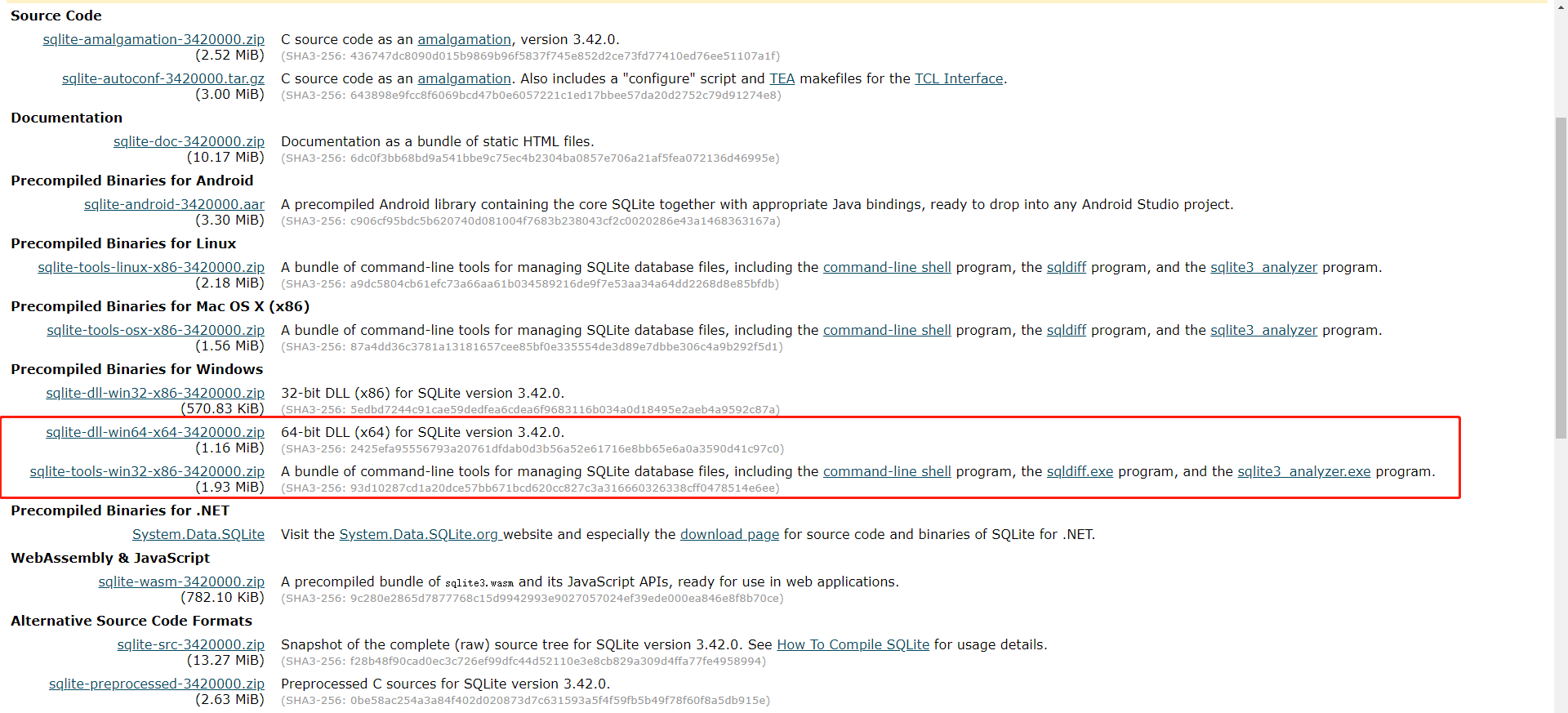
下载完成后解压
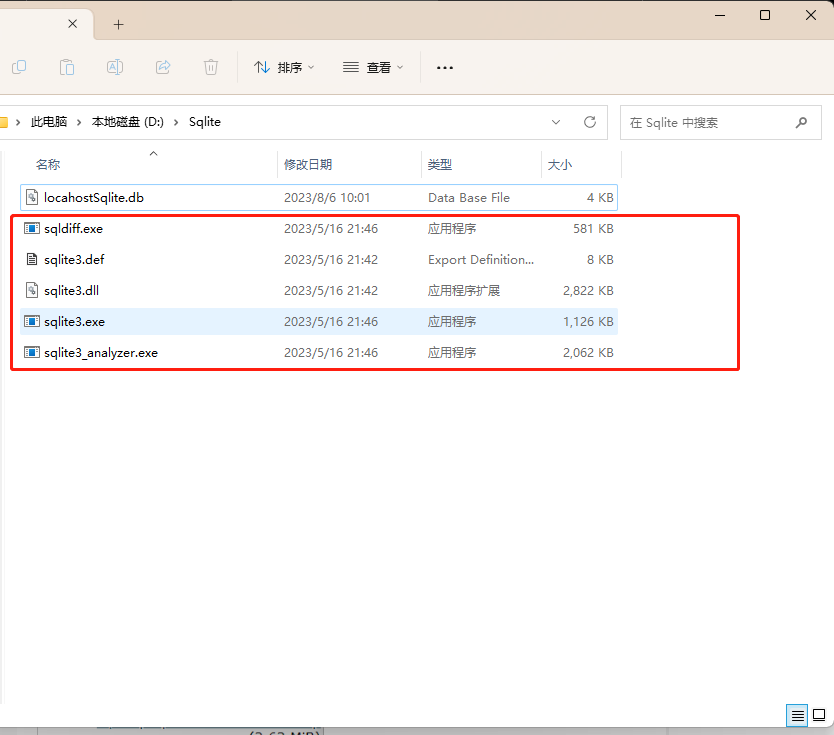
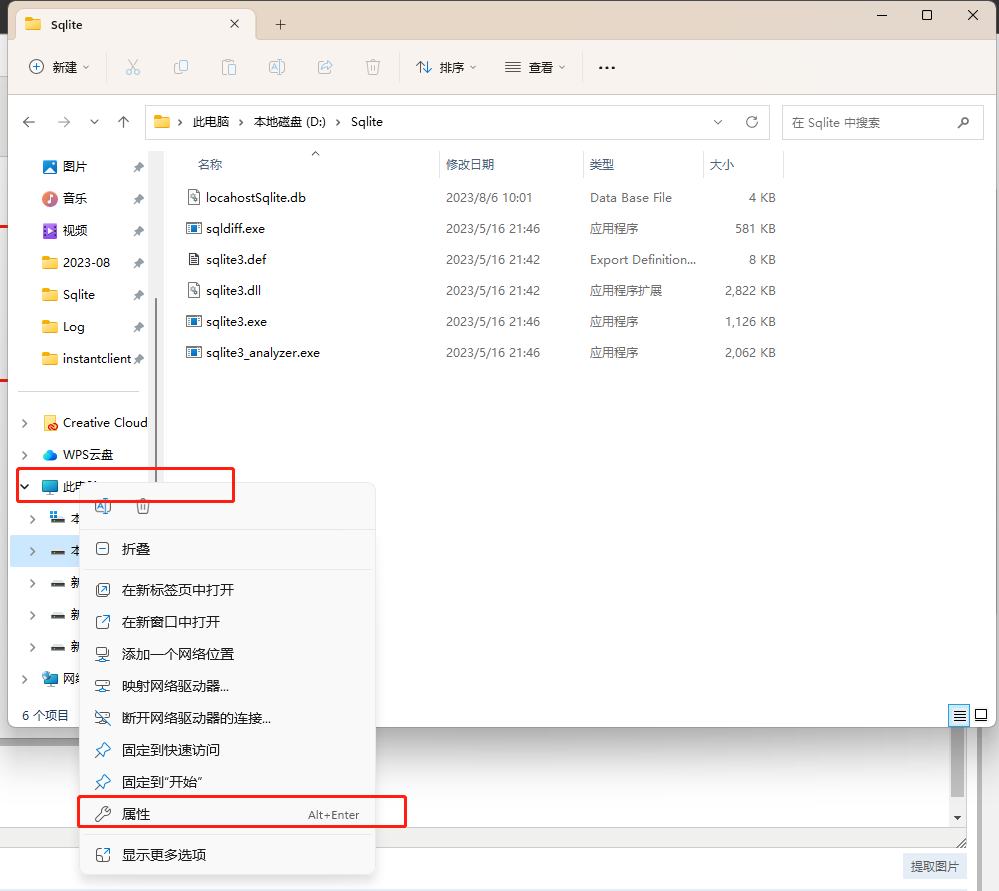
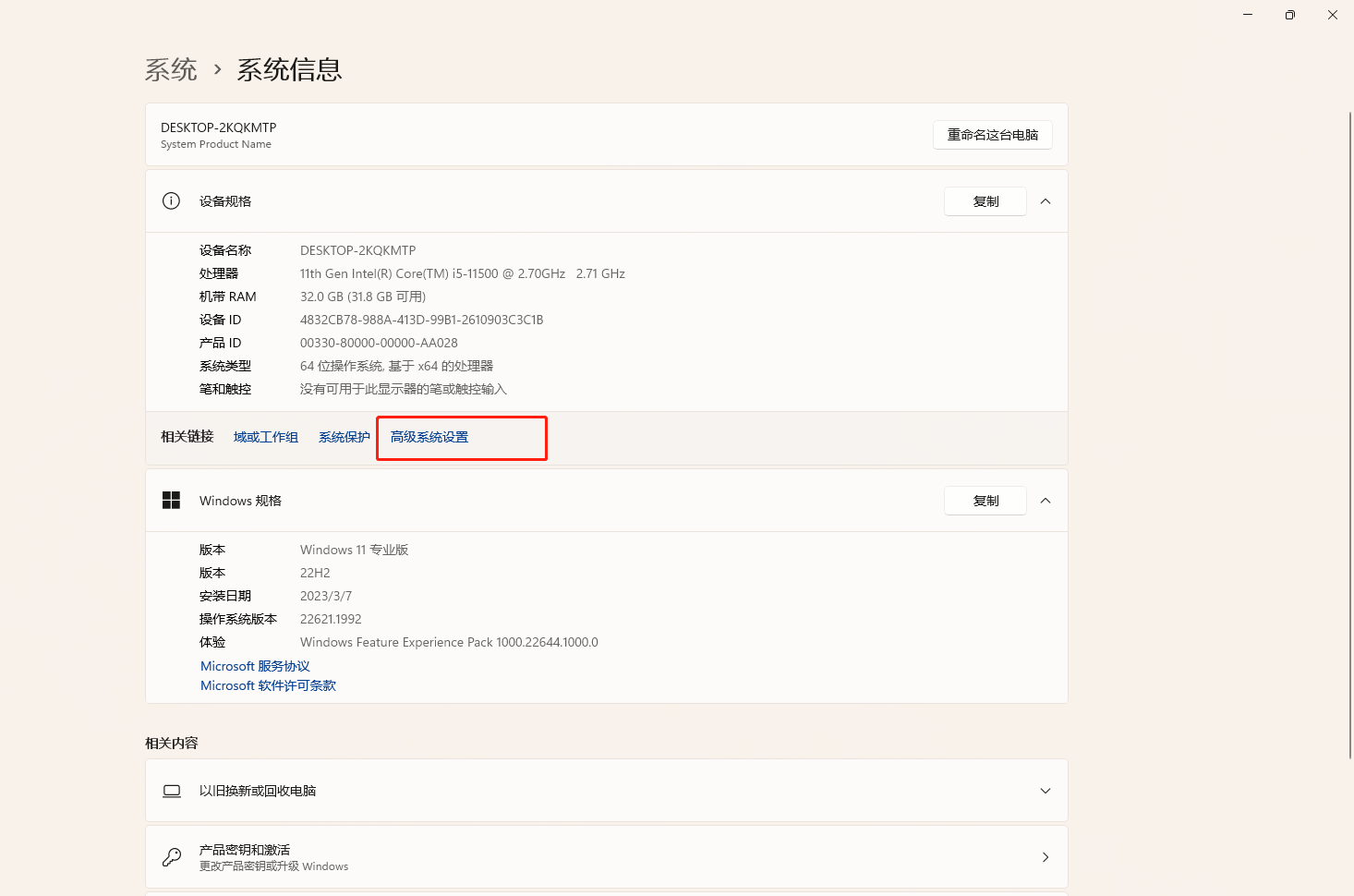
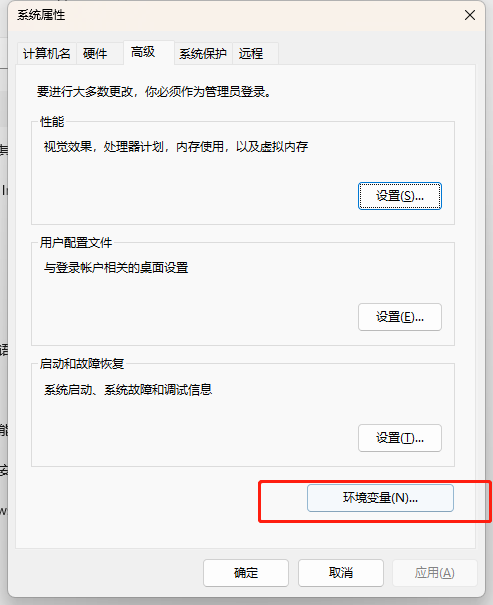
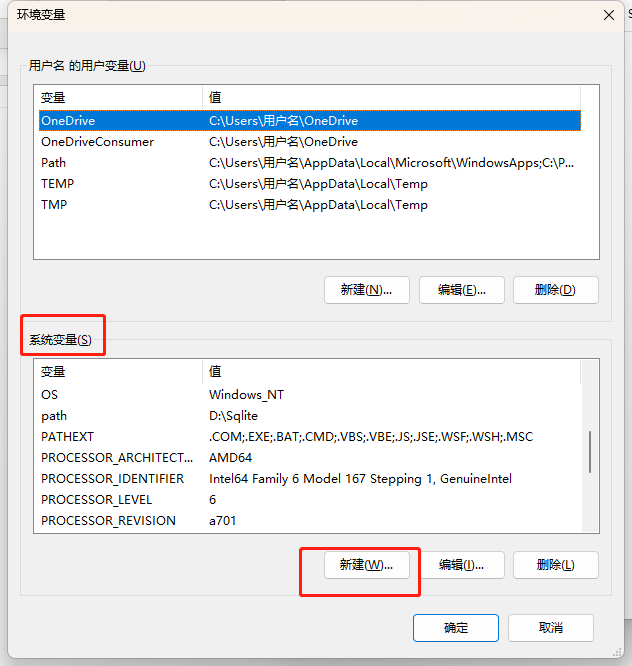
接下来去配置环境变量,右键此电脑->属性->高级系统设置->环境变量->系统变量(新建)->变量名输入path,变量值输入解压出来的sqlite文件路径
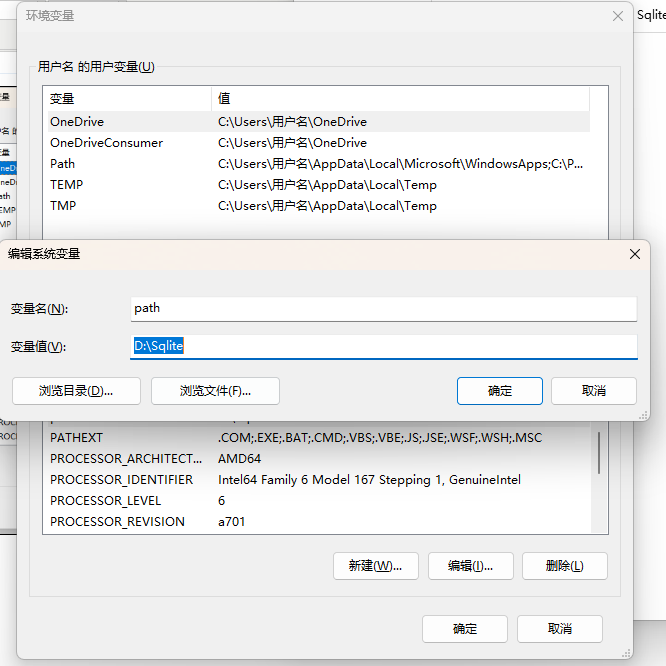
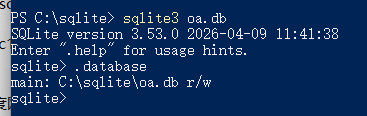
然后cmd测试一下
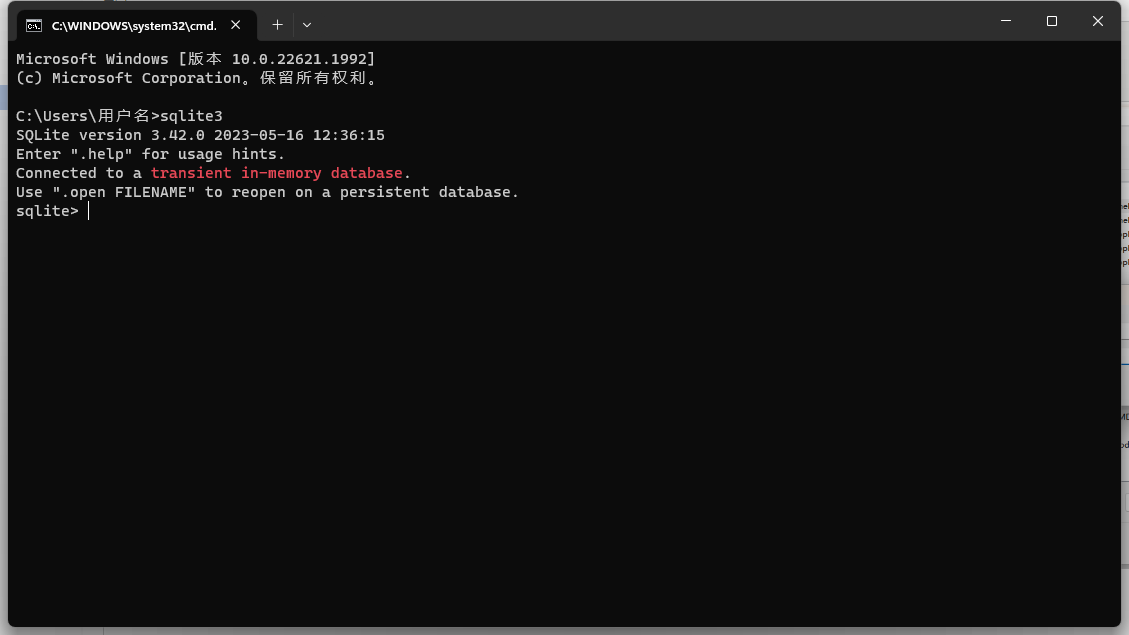
输出版本 安装完成!
1.创建数据库
1 | $sqlite3 DatabaseName.db |

查询数据库列表:
1 | 可以使用 SQLite 的 .database 命令来检查它是否在数据库列表中 |

退出sqlite>提示符:
1 | sqlite>.quit |
导出数据库:
1 2 3 | $sqlite3 testDB.db .dump > testDB.sql上面的命令将转换整个 testDB.db 数据库的内容到 SQLite 的语句中,并将其转储到 ASCII 文本文件 testDB.sql 中。您可以通过简单的方式从生成的 testDB.sql 恢复,如下所示:$sqlite3 testDB.db < testDB.sql |
2.创建表
CREATE TABLE语法:
1 2 3 4 5 6 7 | CREATE TABLE database_name.table_name( column1 datatype PRIMARY KEY(one or more columns), column2 datatype, column3 datatype, ..... columnN datatype,); |
CREATE TABLE 是告诉数据库系统创建一个新表的关键字。CREATE TABLE 语句后跟着表的唯一的名称或标识。您也可以选择指定带有 table_name 的 database_name。
实例:
1 2 3 4 5 6 7 8 | 创建了一个 COMPANY 表,ID 作为主键,NOT NULL 的约束表示在表中创建纪录时这些字段不能为 NULL:sqlite> CREATE TABLE COMPANY( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL); |
其中ID就是作为主键。主键的意思就是唯一标识符。不会出现重复。
ID,NAME,AGE这些都是列,也就是字段。
为什么要有主键?
比如用COMPANY中的NANE这个字段,有可能出现同名同姓的人,那么在这个时候就会出现检索混乱的问题。所以增加主键,作为唯一标识符。
NOT NULL表示这个字段不能为空,必须要填写。
.tables列出数据库所有表:
1 2 | sqlite>.tablesCOMPANY |
.schema列出表的完整信息:
1 2 3 4 5 6 7 8 | sqlite>.schema COMPANYCREATE TABLE COMPANY( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL); |
3.删除表
DROP TABLE语法:
1 | DROP TABLE database_name.table_name; |
实例:
1 2 | sqlite>.tablesCOMPANY |
这意味着 COMPANY 表已存在数据库中,接下来让我们把它从数据库中删除,如下:
1 2 | sqlite>DROP TABLE COMPANY;sqlite> |
现在,如果尝试 .TABLES 命令,那么将无法找到 COMPANY 表了:
1 2 | sqlite>.tablessqlite> |
4.向表中的字段添加数据
INSERT INTO
1 2 | INSERT INTO TABLE_NAME [(column1, column2, column3,...columnN)] VALUES (value1, value2, value3,...valueN); |
在这里,column1, column2,...columnN 是要插入数据的表中的列的名称。也就是要插入到哪个字段。
如果要为表中的所有列添加值,您也可以不需要在 SQLite 查询中指定列名称。但要确保值的顺序与列在表中的顺序一致。SQLite 的 INSERT INTO 语法如下:
1 | INSERT INTO TABLE_NAME VALUES (value1,value2,value3,...valueN); |
实例:

INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (1, 'Paul', 32, 'California', 20000.00 ); INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (2, 'Allen', 25, 'Texas', 15000.00 ); INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (3, 'Teddy', 23, 'Norway', 20000.00 ); INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 ); INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (5, 'David', 27, 'Texas', 85000.00 ); INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (6, 'Kim', 22, 'South-Hall', 45000.00 );
也可以使用第二种语法在 COMPANY 表中创建一个记录,如下所示:
1 | INSERT INTO COMPANY VALUES (7, 'James', 24, 'Houston', 10000.00 ); |
5.获取表中数据
SELECT语法:
1 | SELECT column1, column2, columnN FROM table_name; |
在这里,column1, column2...是表的字段,他们的值即是您要获取的。如果您想获取所有可用的字段,那么可以使用下面的语法:
1 | SELECT * FROM table_name; |
实例:
假设 COMPANY 表有以下记录:
1 2 3 4 5 6 7 8 9 | ID NAME AGE ADDRESS SALARY---------- ---------- ---------- ---------- ----------1 Paul 32 California 20000.02 Allen 25 Texas 15000.03 Teddy 23 Norway 20000.04 Mark 25 Rich-Mond 65000.05 David 27 Texas 85000.06 Kim 22 South-Hall 45000.07 James 24 Houston 10000.0 |
使用 SELECT 语句获取并显示所有这些记录。在这里,前两个命令被用来设置正确格式化的输出。
1 2 3 | sqlite>.header onsqlite>.mode columnsqlite> SELECT * FROM COMPANY; |
最后,将得到以下的结果:
1 2 3 4 5 6 7 8 9 | ID NAME AGE ADDRESS SALARY---------- ---------- ---------- ---------- ----------1 Paul 32 California 20000.02 Allen 25 Texas 15000.03 Teddy 23 Norway 20000.04 Mark 25 Rich-Mond 65000.05 David 27 Texas 85000.06 Kim 22 South-Hall 45000.07 James 24 Houston 10000.0 |
如果只想获取 COMPANY 表中指定的字段,则使用下面的查询:
1 | sqlite> SELECT ID, NAME, SALARY FROM COMPANY; |
上面的查询会产生以下结果:
1 2 3 4 5 6 7 8 9 | ID NAME SALARY---------- ---------- ----------1 Paul 20000.02 Allen 15000.03 Teddy 20000.04 Mark 65000.05 David 85000.06 Kim 45000.07 James 10000.0 |